Il y a deux types d’urgences.
- Celles où ça brûle vraiment : production down, données en danger, clients bloqués, sécurité en alerte.
- Celles où ça brûle parce que quelqu’un crie plus fort que les autres.
Le problème, c’est que si tu ne définis pas clairement le mot urgence, ton système le définit à ta place. Et un système sans règle claire, ça choisit la règle la plus primitive : le volume sonore.
Résultat :
- des tickets “URGENT !!!” pour des icônes mal alignées,
- des devs qui switchent toutes les 15 minutes,
- du support qui promet n’importe quoi pour survivre,
- des managers qui se transforment en standardistes de crise,
- et des vraies urgences qui… passent au milieu du bruit.
Définir l’urgence, ce n’est pas “être rigide”.
C’est l’inverse : c’est créer une exception contrôlée dans un système stable.
Le piège classique : confondre “important”, “urgent” et “visible”
Tu connais la scène.
Un utilisateur envoie :
“Bonjour, j’ai un problème, c’est urgent.”
Tu ouvres : c’est un export Excel qui ne garde pas le format de la colonne U.
Et là, tu as deux options :
- soit tu dis oui, parce que “si je dis non je vais avoir des ennuis”,
- soit tu dis non, parce que “ça n’est pas une urgence”… sans cadre, donc tu passes pour le méchant.
Ce n’est pas une question de courage. C’est une question de définition.
Trois concepts à séparer (sinon tu souffres)
- Important : a de la valeur business / long terme (refonte, dette technique, conformité).
- Urgent : nécessite une action immédiate car le coût du délai explose.
- Visible : beaucoup de monde le voit (ou une personne très influente le voit).
Sans garde-fous, le “visible” se déguise en “urgent”.
Une définition d’urgence qui tient debout
Une urgence n’est pas :
- “ce qui doit être fait aujourd’hui”
- “ce qui stresse”
- “ce qui vient d’un boss”
- “ce qui est client-facing”
Une urgence, c’est un item dont le coût d’attente est supérieur au coût d’interruption.
Ça veut dire quoi concrètement ?
👉 Interrompre le flux a un prix : perte de focus, rework, files d’attente qui gonflent, qualité qui baisse.
👉 Attendre a aussi un prix : pénalités, réputation, pertes de vente, risques légaux/sécurité.
Urgence = quand attendre coûte plus cher que couper le travail en cours.
C’est simple, logique… et surtout, ça se prouve.
Le test en 5 questions (anti-hurlement)
Avant d’appeler “urgence”, on répond à ces 5 questions. Pas besoin de comité. Juste un mini rituel.
- Impact : qui est bloqué, combien, et sur quoi ?
- 1 personne gênée ≠ 500 clients à l’arrêt.
- Dégradation : l’impact augmente-t-il avec le temps ?
- Exemple : risque de perte de données, pénalité, sécurité.
- Contournement : y a-t-il un workaround acceptable ?
- Si oui, ce n’est souvent pas une urgence, c’est une priorité planifiée.
- Délai maximal : que se passe-t-il si on ne touche à rien pendant 2h / 24h / 3 jours ?
- Si la réponse est “rien de grave”, c’est du bruit.
- Responsabilité : qui prend la décision “on interrompt” ?
- Si c’est “tout le monde”, c’est “personne”, donc ça hurle.
Ce test fait déjà un miracle : il oblige à remplacer le mot “urgent” par des faits.
Mets des niveaux d’urgence… mais peu
Tu n’as pas besoin de 12 statuts. Tu as besoin de 3 ou 4 niveaux max, sinon personne ne les utilise correctement.
Exemple de grille simple (adaptable) :
Niveau 1 — Incident critique
- Service indisponible / données menacées / sécurité / obligation légale
- Pas de contournement acceptable
- Action immédiate requise
✅ Traitement : “stop the line” + canal dédié + priorité absolue.
Niveau 2 — Incident majeur
- Dégradation forte, plusieurs utilisateurs/clients impactés
- Contournement partiel possible
- Action rapide (dans la journée, par exemple)
✅ Traitement : file “prioritaire”, pas forcément interruption totale.
Niveau 3 — Standard
- Demande normale, planifiable
- Impact limité ou contournement acceptable
✅ Traitement : flux normal.
Niveau 4 — À planifier
- Amélioration / dette / refonte / demande floue
✅ Traitement : discovery, découpage, priorisation.
Astuce : si tu mets “Niveau 1” trop souvent, c’est que ton niveau 1 est mal défini… ou que ton système est sous-capacité chronique.
La règle d’or : une urgence doit avoir un “contrat de service”
Une urgence sans règle de traitement, c’est juste un mot plus fort.
Quand tu définis une urgence, définis aussi :
- qui intervient
- dans quel délai
- ce qu’on met en pause
- comment on communique
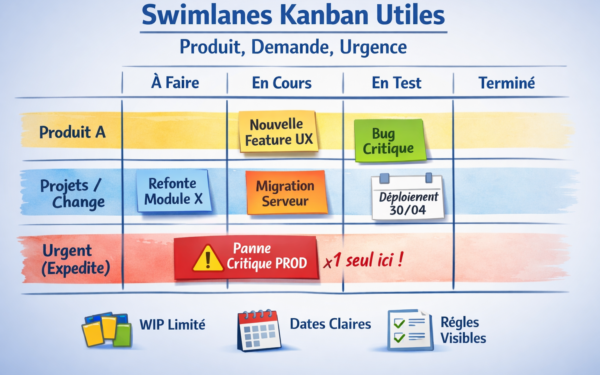
C’est là que Kanban devient ton allié, pas ton tableau de post-its.
Exemple : la “voie express” (Expedite) mais avec barrière
Dans Kanban, on parle souvent de “classe de service” type ExpediteExpediteclasse de service qui court-circuite (presque) tout..
Très bien… à une condition :
ExpediteExpediteclasse de service qui court-circuite (presque) tout. n’est pas une priorité. C’est une exception.
Donc :
- WIPWIPle nombre d’éléments actuellement en cours dans ton système (ton board).En Kanban, le WIP est une variable de contrôle : on le limite volontairement. limite = 1 sur la voie express
- un seul item à la fois (sinon ce n’est plus express, c’est juste “tout le monde passe devant”)
- conditions d’entrée strictes (Niveau 1 ou 2 uniquement)
Si tu autorises 5 urgences simultanées, tu n’as pas 5 urgences.
Tu as une organisation en panique.
Le vrai point sensible : comment dire “non” sans conflit
Dire “ce n’est pas urgent” ne marche pas. Parce que ça ressemble à un jugement.
Ce qui marche :
- “Selon notre définition, ça rentre en Niveau 3.”
- “On peut le traiter en standard, ou on peut escalader, mais alors on mettra X en pause.”
- “On a un contournement, donc on sécurise aujourd’hui et on corrige dans le flux.”
Tu ne refuses pas. Tu appliques une règle commune.
Et surtout : tu rends le coût visible.
La phrase magique (à afficher au mur)
“Si on le met en urgence, qu’est-ce qu’on dépriorise à la place ?”
Une organisation qui hurle veut le bénéfice de l’urgence sans payer son prix.
Toi, tu remets le ticket de caisse sur la table.
Trois exemples concrets (parce que sinon c’est de la théorie)
1) Support / Helpdesk
- Ticket : “Mon mot de passe ne marche pas, URGENT”
- Impact : 1 personne bloquée
- Contournement : reset via procédure
- Délai : 15 min
➡️ Standard, pas “incident critique”
Mais :
- Ticket : “Impossible de se connecter : 200 utilisateurs”
- Impact : massif
- Contournement : aucun
➡️ Incident majeur ou critique, selon service
👉 La différence n’est pas l’émotion. C’est l’impact.
2) Dev / Produit
- “Le bouton est moche sur mobile”
➡️ Visibilité haute, urgence basse. - “Paiement impossible depuis 10h23”
➡️ Urgence réelle, coût du délai énorme.
👉 Si tu ne cadres pas, le design criera plus fort que le paiement (oui, ça arrive).
3) Data / Sécurité
- “Un export met 2 minutes au lieu de 30 secondes”
➡️ irritant, pas urgent. - “Suspicion d’accès non autorisé”
➡️ urgence absolue, même si “personne ne se plaint”.
👉 Les vraies urgences ne sont pas toujours les plus visibles.
Le garde-fou ultime : limiter l’interruption, pas l’urgence
Ton but n’est pas d’avoir zéro urgence.
Ton but est d’avoir une capacité maîtrisée à les absorber sans casser le reste.
Deux pratiques qui changent tout :
1) Un créneau “buffer” (capacité réservée)
Exemple : 20% du temps de l’équipe est réservé aux imprévus.
- Si aucun imprévu : on avance sur la dette / l’amélioration.
- Si imprévu : on n’explose pas la semaine.
Ça évite de transformer chaque surprise en drame.
2) Une revue hebdo des urgences (très courte)
15 minutes.
On regarde :
- combien d’urgences cette semaine ?
- combien étaient légitimes ?
- lesquelles étaient des “urgences de confort” ?
- quelle cause racine revient ?
Le but n’est pas de blâmer.
Le but est de réduire le débitThroughputle nombre d’items terminés sur une période donnée.Ex : 18 tickets “Done” cette semaine → throughput = 18/semaine. d’urgences à la source.
Parce que l’urgence, c’est souvent le symptôme de :
- monitoring absent,
- processus cassé,
- dépendance non gérée,
- dette technique,
- manque de capacité,
- ou promesses commerciales sans coordination.
La punchline (à garder pour toi si tu veux)
Une organisation qui hurle n’a pas “trop d’urgences”.
Elle a :
- trop peu de règles,
- trop peu de visibilité sur le coût du délai,
- et un système de priorisation remplacé par l’émotion.
Définir l’urgence, c’est remettre du calme dans le système.
Pas pour être gentil. Pour être efficace.
Mini kit prêt à copier-coller (politique d’urgence)
Tu peux mettre ça dans ton wiki / outil de ticketing :
- Une urgence = impact critique + pas de contournement + coût du délai supérieur au coût d’interruption.
- Niveaux : Critique / Majeur / Standard / Planifié.
- Entrée “Critique” : service down, sécurité, données, obligation légale, paiement bloqué.
- Voie express (ExpediteExpediteclasse de service qui court-circuite (presque) tout.) : WIPWIPle nombre d’éléments actuellement en cours dans ton système (ton board).En Kanban, le WIP est une variable de contrôle : on le limite volontairement.=1, décision par [rôle/astreinte], communication sur [canal], post-mortem léger obligatoire.
- Règle : toute urgence implique un arbitrage explicite (“qu’est-ce qu’on met en pause ?”).
- Revue : 15 min chaque semaine pour analyser les urgences et réduire leur source.